Despite the growing capability of end-to-end autonomous driving (E2EAD) systems, personalization remains largely overlooked. Aligning driving behavior with individual user preferences is essential for comfort, trust, and real-world deployment— but existing datasets and benchmarks lack the necessary structure and scale to support this goal.
StyleDrive bridges this gap with the following key contributions:
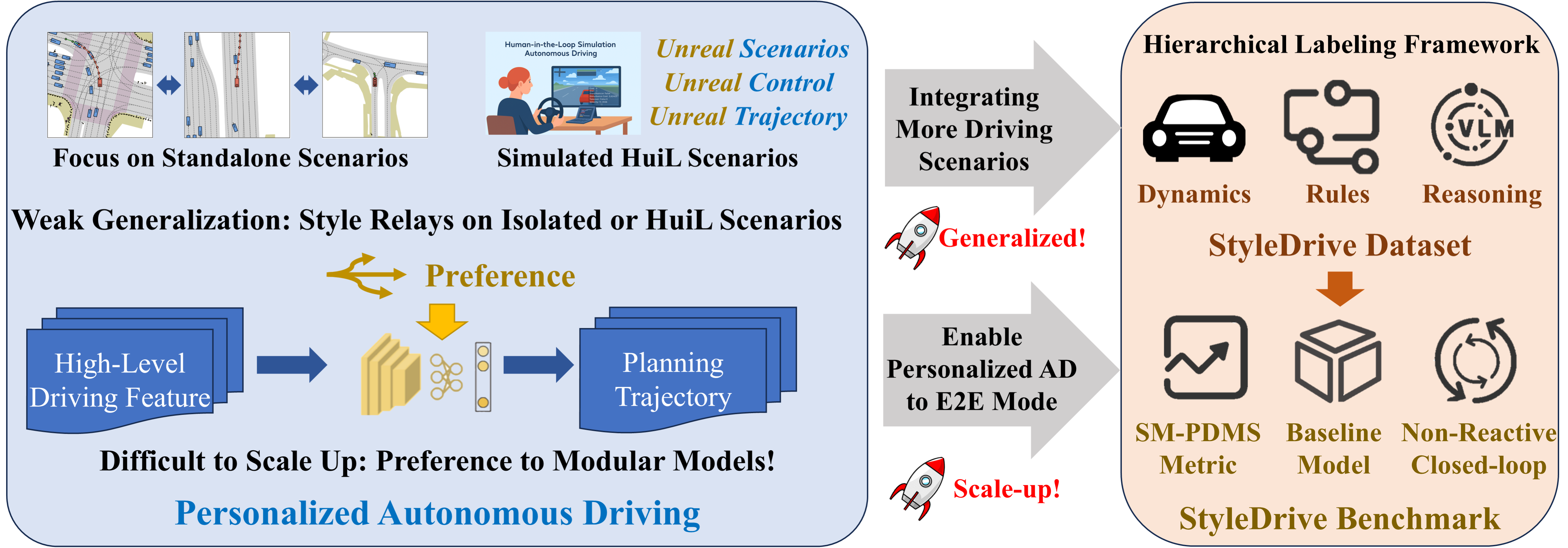
The figure illustrates the motivation and overview of StyleDrive. Users increasingly expect AVs not just to drive safely—but to drive like them. Integrating personalization into E2EAD is challenging due to (1) the lack of real-world datasets with style annotations enabling E2EAD, and (2) limited architectures consider style preference as condition in E2E manner. To bridge this gap, we present the first real-world dataset and benchmark tailored for personalized E2EAD.
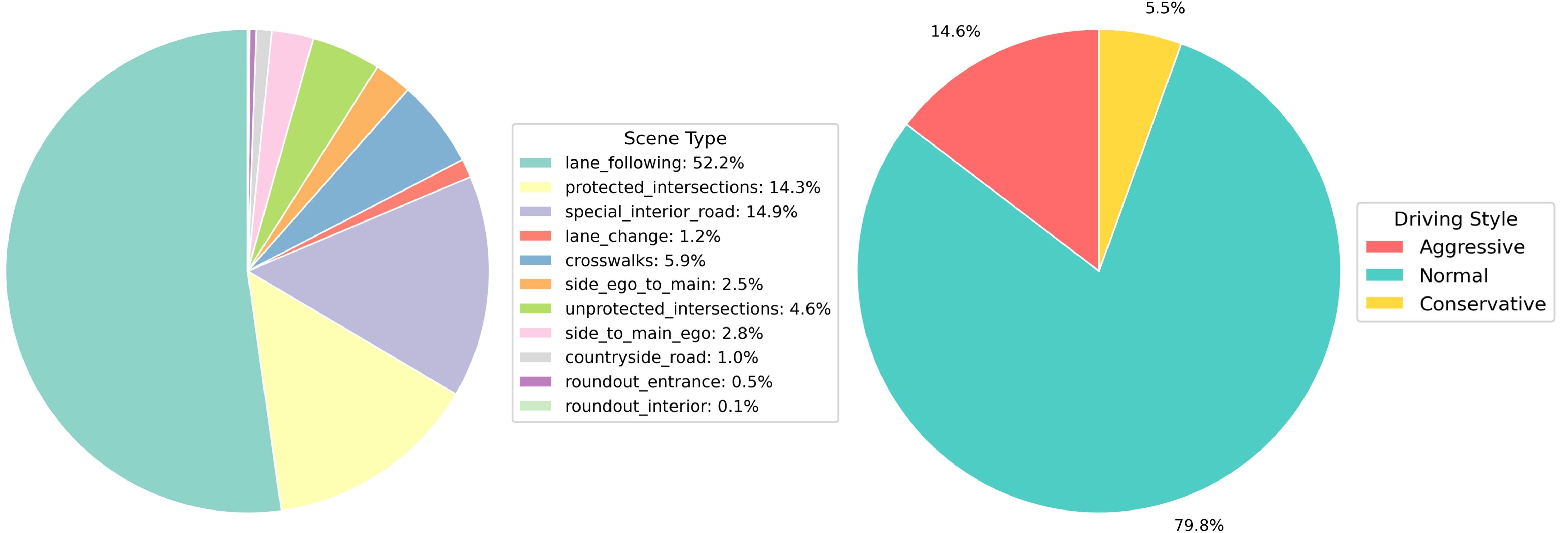
StyleDrive is the first large-scale real-world dataset tailored for personalized end-to-end autonomous driving (E2EAD). It is constructed on top of the OpenScene dataset, and contains nearly 30,000 driving scenarios across urban and rural environments.
Each scenario is annotated with both:
To ensure high-quality and interpretable annotations, we propose a multi-stage labeling pipeline:
The dataset spans 11 real-world traffic scenario types (e.g., intersections, merges, roundabouts), and provides per-scenario safety scores, relative positioning, and temporal style labels.
With its hybrid annotation strategy and diverse behavior coverage, StyleDrive offers a unique resource for modeling, analyzing, and benchmarking human-aligned autonomous driving.
The StyleDrive dataset is constructed via a multi-stage annotation pipeline designed to capture both low-level behavior and high-level style preferences, grounded in rich semantic contexts.
The process begins by segmenting raw driving clips into traffic scenarios using high-definition map topology. Within each segment, semantic context—such as proximity to lead vehicles, pedestrians, or lane merges—is extracted through a fine-tuned Vision-Language Model (VLM), enabling interpretable behavioral grounding.
Style labeling is performed in three key stages:
A risk-aware fusion strategy combines rule-based and VLM outputs, yielding consistent, interpretable, and scalable style labels. The final dataset includes style annotations across 11 real-world traffic scenario types, enabling robust personalized driving policy learning.
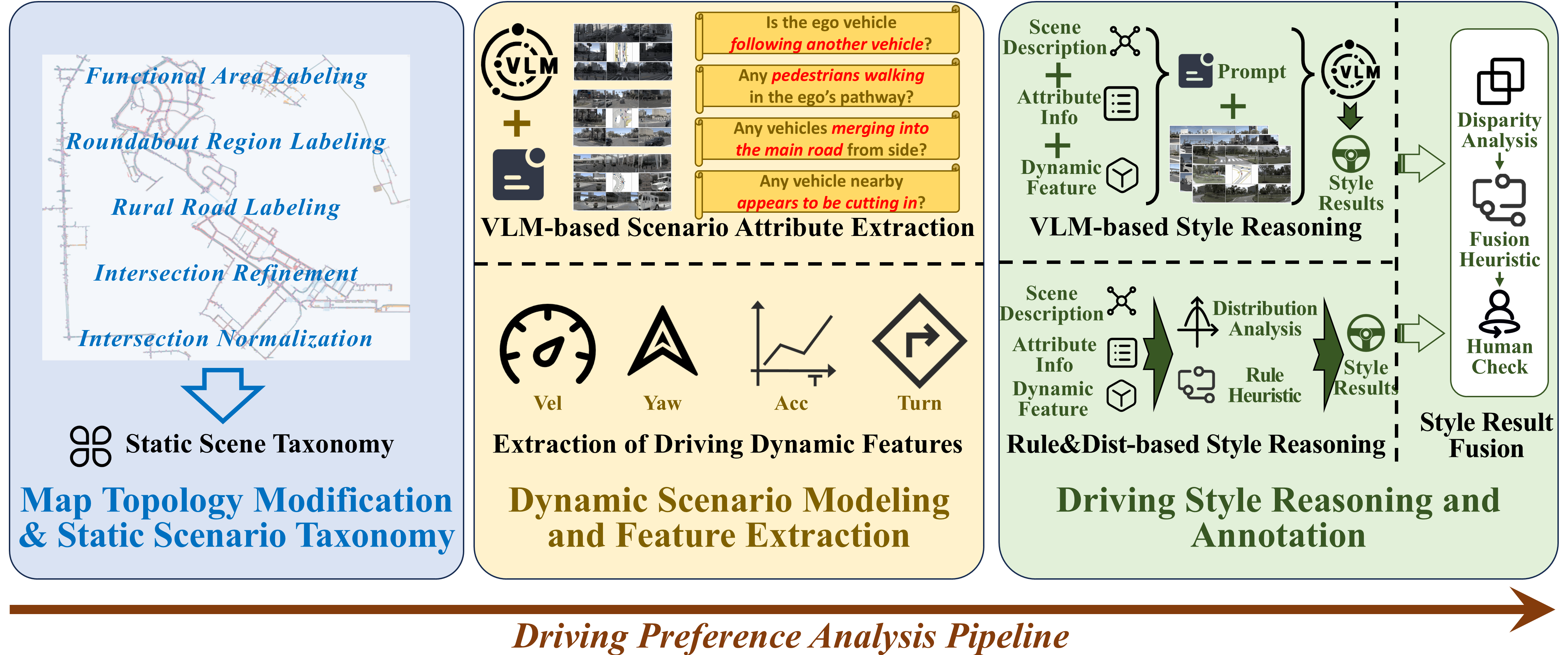
Annotation pipeline integrating topology segmentation, semantic extraction, rule-based analysis, VLM inference, and human verification.
Each annotated sample in the StyleDrive dataset encapsulates a wide array of semantic, dynamic, and contextual attributes, enabling rich representation of driving behaviors and personalized preferences. The data schema is designed to support learning models that condition on style, motion, perception, and safety cues.
Below is a representative structure of one data entry:
| Field | Description |
|---|---|
| vx_ego, vy_ego, v_ego | Velocity vector (x, y) and magnitude of ego vehicle |
| ax_ego, ay_ego, a_ego | Acceleration vector and overall acceleration |
| yaw, yaw_diff | Heading angle and angular change across frames |
| v_avg, v_std | Average and variability of velocity (last 10 frames) |
| vy_max | Peak lateral velocity (side-slip indicator) |
| a_max, a_std, ax_avg | Max, std of acceleration and average forward acceleration |
| ini_direction_judge | Initial motion direction classification |
| scenario_type | Semantic scenario type parsed from VLM (e.g., roundabout, crosswalk) |
| scene_token | Globally unique identifier for each driving scene |
| has_left_rear / right_rear | Flags indicating rear adjacent vehicles |
| left_rear_min / right_rear_min | Minimum distances to left/right rear vehicles |
| speed_mode | Preferred driving style label (Aggressive, Normal, Conservative) |
| front_frame | Temporal distance series to front vehicle |
| safe_frame | Boolean safety labels per frame |
| safe_ratio, unsafe_ratio, oversafe_ratio | Style-based safety distribution over entire scenario |
The structured schema supports learning from motion, interaction, semantics, and style.
The following videos highlight how aggressive, normal, and conservative agents adapt differently to the same initial environment.
Left Turn
Given similar initial conditions for a left-turn maneuver, after 7 seconds, the aggressive driver (left) exhibits higher acceleration and covers the greatest progress, the normal driver (center) progresses moderately toward the intersect center, and the conservative one (right) initiates movement slowly, leading to mini displacement.
Right Turn
Given similar initial conditions for a merge-into-sideway without pedestrian crossing, after 7 seconds, the aggressive driver (left) exhibits higher acceleration and covers the greatest progress, ignoring potential sudden pedestrians, the normal driver (center) progresses moderately, and the conservative one (right) initiates movement slowly and cautiously.
Side ego to Main
Given similar initial conditions for a side-to-ego scenario (with ego on the side road), after 7 seconds, the aggressive driver (left) cuts into the vehicle queue, exhibiting the highest acceleration and greatest progress. The normal driver (center) brakes to yield space for vehicles on the main road, while the conservative driver (right) cautiously remains in a braking state for several seconds, even after the main road vehicle has yielded.
Side to Main ego
Given similar initial conditions for a side-to-ego scenario (with ego on the main road), after 7 seconds, the aggressive driver (left) ignores the merging vehicle and maintains high speed to pass the merge point; the normal driver (center) decelerates moderately but still passes before the merging vehicle; whereas the conservative driver (right) maintains a large gap from the lead vehicle and even brakes to yield space for the merging vehicle.
Special Interiod Road
Given similar initial conditions for an interior-road scenario, after 7 seconds, the aggressive driver (left) exhibits higher speed and covers the greatest progress, ignoring potential sudden pedestrian emergence or vehicle merging in, the normal driver (center) progresses moderately, and the conservative one (right) moves slowly and cautiously in this complex scenario.
StyleDrive includes 11 diverse real-world traffic scenarios, capturing personalized driving behaviors across structured and unstructured environments.
Crosswalks
Navigating pedestrian crossings with varying yielding behaviors
Lane Following
Maintaining lane center under speed and curvature variations
Protected Intersections
Turning or crossing with clear traffic signals or stop signs
Unprotected Intersections
Negotiating multi-agent crossings without explicit right-of-way
Lane Change
Executing safe or assertive lane shifts in dense or sparse traffic
Side Ego to Main
Entering a main road from a side street with merging considerations
Side to Main Ego
Ego vehicle on main road encounters merging side traffic
Special Interior Road
Driving through complex local environments like alleys, parking, or loops
Countryside Road
Navigating long, curved roads with sparse surrounding vehicles
Roundabout Interior
Maintaining trajectory inside multi-lane roundabout with potential exits
Roundabout Entrance
Merging into circular flow under dynamic vehicle interactions
The StyleDrive Benchmark introduces a standardized evaluation suite for personalized end-to-end autonomous driving. It extends the StyleDrive dataset into a closed-loop testing environment built upon the NavSim simulator, allowing models to be evaluated in realistic, interactive traffic scenes.
At the core of this benchmark is the Style-Modulated Predictive Driver Model Score (SM-PDMS). This metric jointly captures:
Evaluation is conducted under three canonical driving styles — Aggressive, Normal, and Conservative. Each policy is conditioned on a target style label and deployed in multiple real-world driving contexts.
We implement baseline controllers spanning multiple model families — including MLP-based predictors, transformer architectures, and diffusion-policy networks. Experimental results consistently demonstrate that style-aware models achieve higher SM-PDMS scores and produce behaviors more closely aligned with human demonstrations.
This benchmark provides a reproducible, quantitative platform for evaluating style-conditioned policy learning. It serves as a crucial step toward developing human-aligned, preference-aware driving agents in real-world environments.
The following table summarizes the performance of various E2EAD models under style-conditioned evaluation using the SM-PDMS framework. Higher scores indicate better feasibility and alignment with target driving preferences.
| Model | NC ↑ | DAC ↑ | TTC ↑ | Comf. ↑ | EP ↑ | SM-PDMS ↑ |
|---|---|---|---|---|---|---|
| AD-MLP | 92.63 | 77.68 | 83.83 | 99.75 | 78.01 | 63.72 |
| TransFuser | 96.74 | 88.43 | 91.08 | 99.65 | 84.39 | 78.12 |
| WoTE | 97.29 | 92.39 | 92.53 | 99.13 | 76.31 | 79.56 |
| DiffusionDrive | 96.66 | 91.45 | 90.63 | 99.73 | 80.39 | 79.33 |
| AD-MLP-Style | 92.38 | 73.23 | 83.14 | 99.90 | 78.55 | 60.02 |
| TransFuser-Style | 97.23 | 90.36 | 92.61 | 99.73 | 84.95 | 81.09 |
| WoTE-Style | 97.58 | 93.44 | 93.70 | 99.26 | 77.38 | 81.38 |
| DiffusionDrive-Style | 97.81 | 93.45 | 92.81 | 99.85 | 84.84 | 84.10 |
The following table summarizes the performance of DiffusionDrive-Style model under Fixed style-conditioning. This ablation results further confirm the effectiveness and learnability of style conditioning.
| Model | NC ↑ | DAC ↑ | TTC ↑ | Comf. ↑ | EP ↑ | SM-PDMS ↑ |
|---|---|---|---|---|---|---|
| DiffusionDrive-Style | 97.81 | 93.45 | 92.81 | 99.85 | 84.84 | 84.10 |
| DiffusionDrive-Style-A | 97.38 | 93.20 | 92.01 | 99.62 | 84.01 | 83.04 |
| DiffusionDrive-Style-A | 97.66 | 93.32 | 92.16 | 99.83 | 84.21 | 83.52 |
| DiffusionDrive-Style-A | 98.23 | 93.59 | 94.98 | 99.87 | 81.36 | 83.90 |
We further evaluate trajectory-level similarity via L2 error across prediction horizons. Style-aware models consistently reduce average L2 distance, indicating stronger alignment with human-like driving behavior.
| Model | L2 (2s) ↓ | L2 (3s) ↓ | L2 (4s) ↓ | L2 Avg ↓ |
|---|---|---|---|---|
| WoTE | 0.733 | 1.434 | 2.349 | 1.506 |
| AD-MLP | 0.503 | 1.262 | 2.383 | 1.382 |
| TransFuser | 0.431 | 0.963 | 1.701 | 1.032 |
| DiffusionDrive | 0.471 | 1.086 | 1.945 | 1.167 |
| WoTE-Style | 0.673 | 1.340 | 2.223 | 1.412 |
| AD-MLP-Style | 0.510 | 1.230 | 2.321 | 1.354 |
| TransFuser-Style | 0.424 | 0.937 | 1.656 | 1.006 |
| DiffusionDrive-Style | 0.417 | 0.940 | 1.646 | 1.001 |
To further analyze the impact of style-conditioning, we visualize DiffusionDrive-Style predictions under controlled scenario conditions. The same traffic environment is used while varying only the driving style input: Aggressive, Normal, and Conservative.
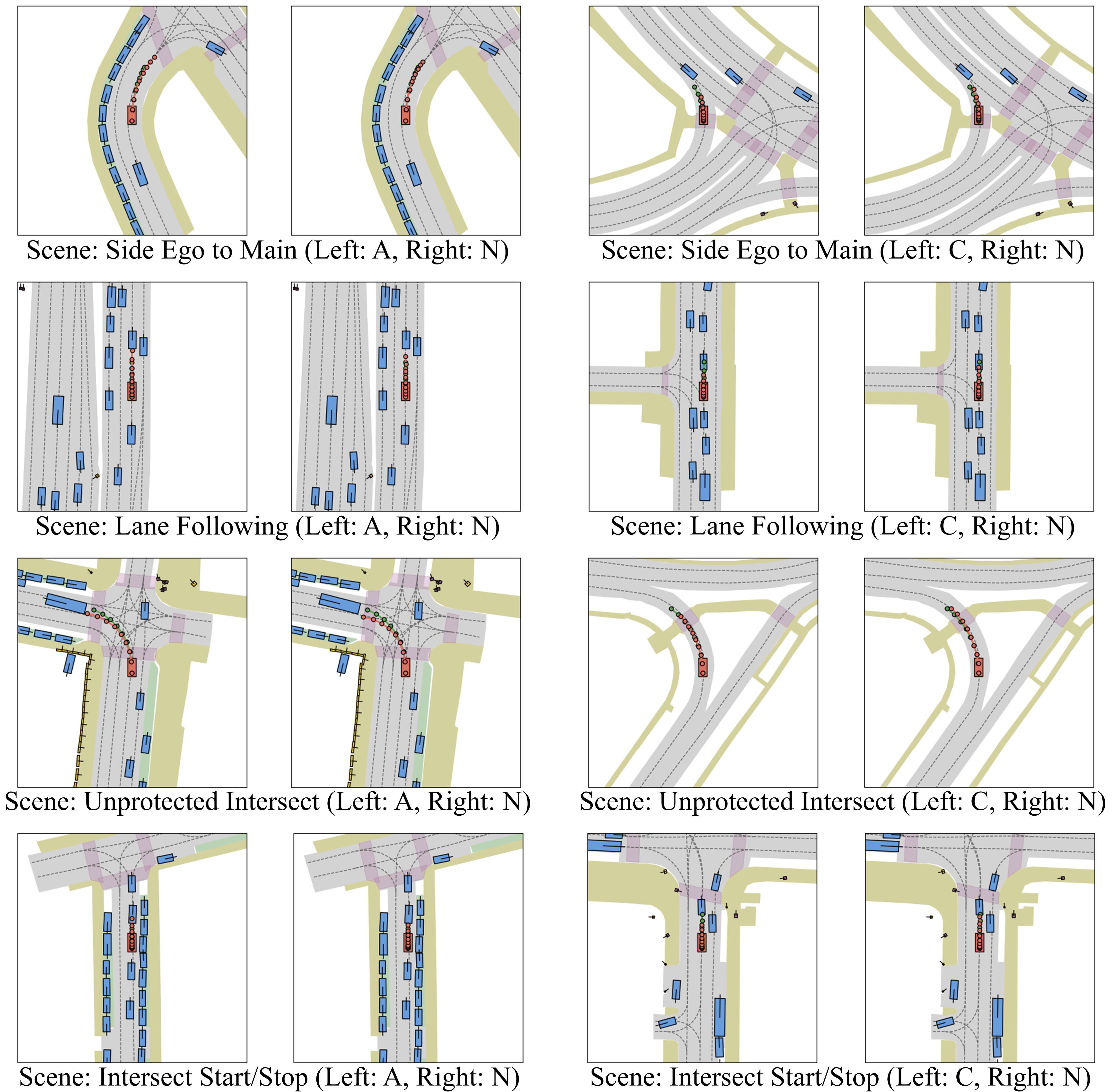
Red dotted lines represent predicted trajectories generated by the model under each style condition, while green dotted lines show the corresponding human demonstrations. Distinct patterns emerge:
Evaluate your model on the StyleDrive Benchmark and see how it ranks.
If you find StyleDrive useful in your research, please consider citing:
@article{hao2025styledrive,
title={StyleDrive: Towards Driving-Style Aware Benchmarking of End-To-End Autonomous Driving},
author={Hao, Ruiyang and Jing, Bowen and Yu, Haibao and Nie, Zaiqing},
journal={arXiv preprint arXiv:2506.23982},
year={2025}
}